GPTBotブロック:ウェブサイトの新たな対応戦略
GPTBotとは何か?
GPTBotは、OpenAIによって開発された最先端のAIボットです。このボットは、ウェブサイトのコンテンツをクロールし、情報を収集することで、AIモデルのトレーニングに利用されます。しかし、この技術の進歩に伴い、多くのウェブサイト運営者はGPTBotのアクセスをブロックすることを選択しています。
トップ1000ウェブサイトのGPTBotブロック状況
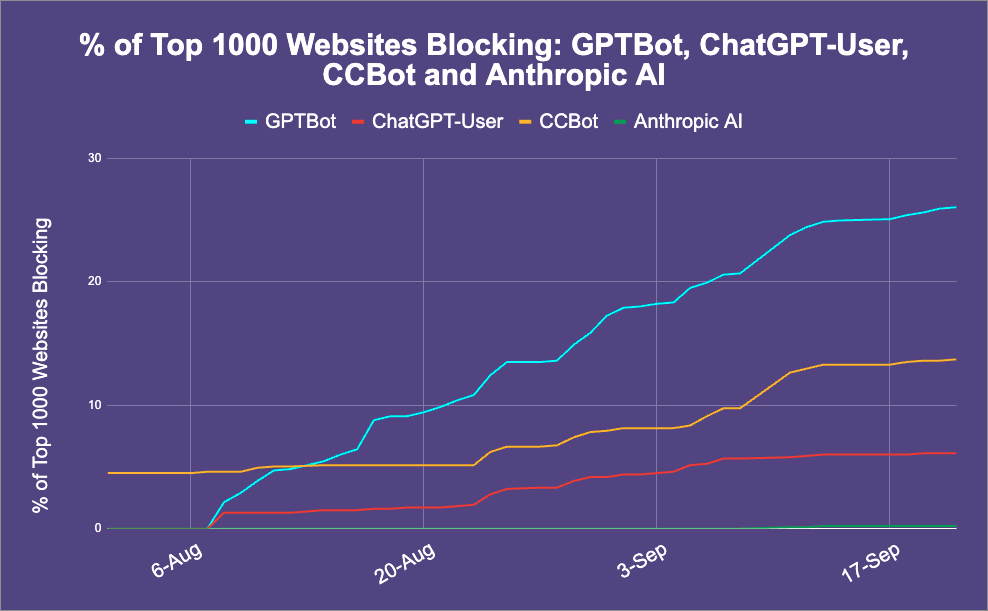
2023年9月22日の研究によると、世界のトップ1000ウェブサイトのうち約26%がGPTBotをブロックしています。この動きは、ウェブサイトのコンテンツ保護と知的財産の管理に対する新たなアプローチを示しています。
GPTBotをブロックする主要なウェブサイト
- Amazon
- Quora
- Indeed
さらに、多くの大手メディアやニュース出版社もGPTBotのブロックに動いています。これには、NYTimes、TheGuardian、CNN.comなどが含まれます。
他のAIボットとの比較
GPTBot以外にも、Common Crawl Bot(CCBot)やAnthropic AIなどの他のAIボットが存在します。しかし、これらのボットはGPTBotほど広範にブロックされていません。CCBotは約14%のウェブサイトでブロックされており、Anthropic AIはごく少数のサイトでのみブロックされています。
Common Crawl Botとは
Common Crawl Botは、ウェブの情報を収集するために使用されるクローラー(またはボット)の1つです。Common Crawlプロジェクトは、ウェブ全体の情報を収集し、インターネットの歴史的なアーカイブを作成することを目的としています。このプロジェクトでは、Common Crawl Botと呼ばれるクローラーがウェブページを自動的にインデックス化し、そのデータを一般の人々や研究者、デベロッパーなどが利用できる形で提供しています。
Common Crawl Botは、以下のような主な特徴を持っています:
- 大規模なウェブスクレイピング: Common Crawl Botは、数億以上のウェブページを収集し、定期的に新しいデータを追加しています。これにより、ウェブ上の情報の包括的なアーカイブが実現されています。
- 非営利的なプロジェクト: Common Crawlプロジェクトは非営利的な性格を持ち、ウェブ上の情報を共有し、誰もが利用できるようにすることを目指しています。そのため、Common Crawlのデータは一般に無料でアクセスできます。
- 研究とデータ解析: 研究者やデータサイエンティストは、Common Crawlのデータを利用してウェブトレンドの分析や研究プロジェクトを行うことができます。また、機械学習モデルのトレーニングにも利用されます。
- ウェブアーカイブ: Common Crawlのデータは、ウェブの歴史的な瞬間や過去のウェブページのアーカイブとしても使用されています。これにより、ウェブの変遷や進化を追跡することが可能です。
Common Crawl Botは、ウェブの情報を公平かつ包括的に収集し、多くの分野で活用されている重要なクローラーの一つです。
Anthropic AIとは
Google Extendedの役割
Googleは、ウェブサイトのコンテンツの使用方法をより細かく制御するための「Google Extended」を導入しました。これにより、ウェブサイト運営者はGoogleのAIボットの使用をより詳細に管理できるようになります。
Google Extendedとは
Googleは、Google-Extendedという新しいユーザーエージェントを追加しました。これにより、ウェブサイト運営者は、BardおよびVertex AI generative APIが生成するAIによる自サイトのコンテンツの利用を制御できるようになります。
ウェブサイトのコンテンツをGoogleのAIに使用されたくない場合、Google-Extendedをrobots.txtでブロックすることが推奨されます。以下のようにrobots.txtに記述することで、サイト内のすべてのコンテンツの利用を拒否できます。
User-Agent: Google-Extended
Disallow: /
Google-Extendedによるクロール制御は、現在のモデルだけでなく、将来リリースされる世代のモデルにも適用されます。ただし、Google-Extendedは実際には存在しないクローラであり、個別のHTTPリクエストユーザーエージェント文字列を持っていません。クローリングは既存のGoogleユーザーエージェント文字列で行われ、robots.txtユーザーエージェントトークンが制御機能として使用されます。
このため、サーバーのログファイルにはGoogle-Extendedは記録されない可能性があります。しかし、BardとVertex AI generative APIのトレーニングに自分のサイトのコンテンツを使わせたくない場合は、Google-Extendedをrobots.txtでブロックすることが重要です。
GPTBotブロックの方法
ウェブサイトは、robots.txtファイルに特定のコードを追加することでGPTBotをブロックできます。この方法は、ウェブサイトのコンテンツを保護し、不正なクローリングから守るための効果的な手段です。
ブロックのメリットとデメリット
GPTBotをブロックすることには、メリットとデメリットがあります。メリットとしては、ウェブサイトのコンテンツが保護され、知的財産が守られることが挙げられます。一方で、デメリットとしては、将来的にAI技術がウェブサイトのトラフィックを増やす可能性があるため、その機会を逃すリスクがあります。
まとめ
GPTBotのブロックは、ウェブサイト運営者が直面する新たな課題です。この動きは、AI技術の進化に伴うウェブサイトのコンテンツ保護と知的財産管理の重要性を示しています。ウェブサイト運営者は、GPTBotをブロックすることのメリットとデメリットを慎重に検討し、適切な対応策を講じる必要があります。
テック系ライターとして、私はこの研究がAI技術の進化とウェブサイトの相互作用における重要なトレンドを浮き彫りにしていると考えています。ウェブサイトがAIボットをブロックすることは、短期的にはコンテンツの保護に役立つかもしれませんが、長期的には新しい技術の恩恵を受ける機会を逃すリスクもあります。AI技術の進化に伴い、ウェブサイト運営者はこれらの新しいツールとどのように共存していくかを慎重に考える必要があります。
参照元: Websites That Have Blocked OpenAI’s GPTBot CCBot Anthropic Google Extended – 1000 Website Study


コメント